Introduction¶
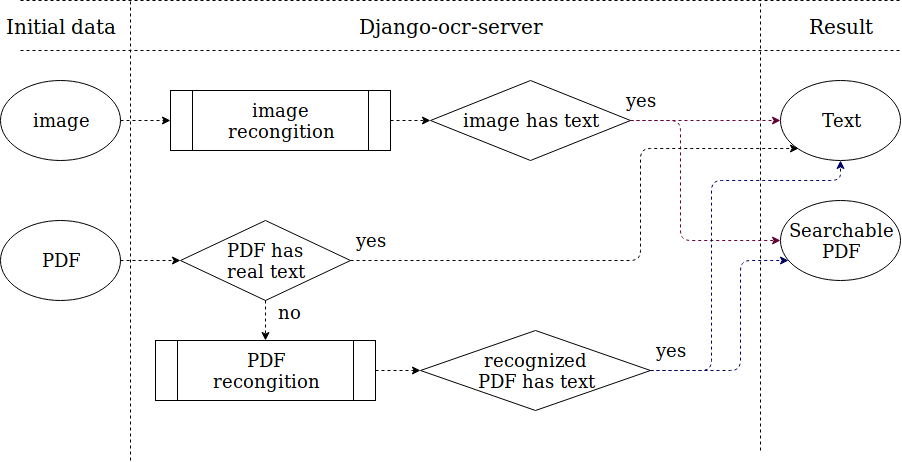
Django-ocr-server lets you recognize images and PDF. It is using tesseract for this. https://github.com/tesseract-ocr/tesseract
Django-ocr-server saves the result in the database. To prevent repeated recognition of the same file, it also saves the hash sum of the uploaded file. Therefore, when reloading an already existing file, the result returns immediately, bypassing the recognition process, which significantly reduces the load on the server.
If as a result of recognition a non-empty text is received, a searchable PDF is created.
For the searchable PDF is calculated hash sum too. Therefore, if you upload the created by Django-ocr-server searchable pdf to the server back, then this file will not be recognized, but the result will be immediately returned.
The server can process not only images, but PDF. At the same time, he analyzes, if the PDF already contains real text, this text will be used and the file will not be recognized, which reduces the load on the server and improves the quality of the output.
Storage of downloaded files and created searchable PDFs can be disabled in the settings.
For uploaded files and created searchable PDFs, and the processing results whole in the settings you can specify the lifetime after which the data will be automatically deleted.
To interact with Django-ocr-server you can use API or the admin interface.